Apache Kafka meets Wayang - Part 1

Intro
This article is the first of a four part series about federated data analysis using Apache Wayang. The first article starts with an introduction of a typical data colaboration scenario which will emerge in our digital future.
In part two and three we will share a summary of our Apache Kafka client implementation for Apache Wayang. We started with the Java Platform (part 2) and the Apache Spark implementation follows (W.I.P.) in part three.
The use case behind this work is an imaginary data collaboration scenario. We see this example and the demand for a solution already in many places. For us this is motivation enough to propose a solution. This would also allow us to do more local data processing, and businesses can stop moving data around the world, but rather care about data locality while they expose and share specific information to others by using data federation. This reduces complexity of data management and cost dramatically.
For this purpose, we illustrate a cross organizational data sharing scenario from the finance sector soon. This analysis pattern will also be relevant in the context of data analysis along supply chains, another typical example where data from many stakeholder together is needed but never managed in one place, for good reasons.
Data federation can help us to unlock the hidden value of all those isolated data lakes.
A cross organizational data sharing scenario
Our goal is the implementation of a cross organization decentralized data processing scenario, in which protected local data should be processed in combination with public data from public sources in a collaborative manner. Instead of copying all data into a central data lake or a central data platform we decided to use federated analytics. Apache Wayang is the tool we work with. In our case, the public data is hosted on publicly available websites or data pods. A client can use the HTTP(S) protocol to read the data which is given in a well defined format. For simplicity we decided to use CSV format. When we look into the data of each participant we have a different perspective.
Our processing procedure should calculate a particular metric on the local data of each participant. An example of such a metric is the average spending of all users on a particular product category per month. This can vary from partner to partner, hence, we want to be able to calculate a peer-group comparison so that each partner can see its own metric compared with a global average calculated from contributions by all partners. Such a process requires global averaging and local averaging. And due to governance constraints, we can’t bring all raw data together in one place.
Instead, we want to use Apache Wayang for this purpose. We simplify the procedure and split it into two phases. Phase one is the process, which allows each participant to calculate the local metrics. This requires only local data. The second phase requires data from all collaborating partners. The monthly sum and counter values per partner and category are needed in one place by all other parties. Hence, the algorithm of the first phase stores the local results locally, and the contributions to the global results in an externally accessible Kafka topic. We assume this is done by each of the partners.
Now we have a scenario, in which an Apache Wayang process must be able to read data from multiple Apache Kafka topics from multiple Apache Kafka clusters but finally writes into a single Kafka topic, which then can be accessed by all the participating clients.
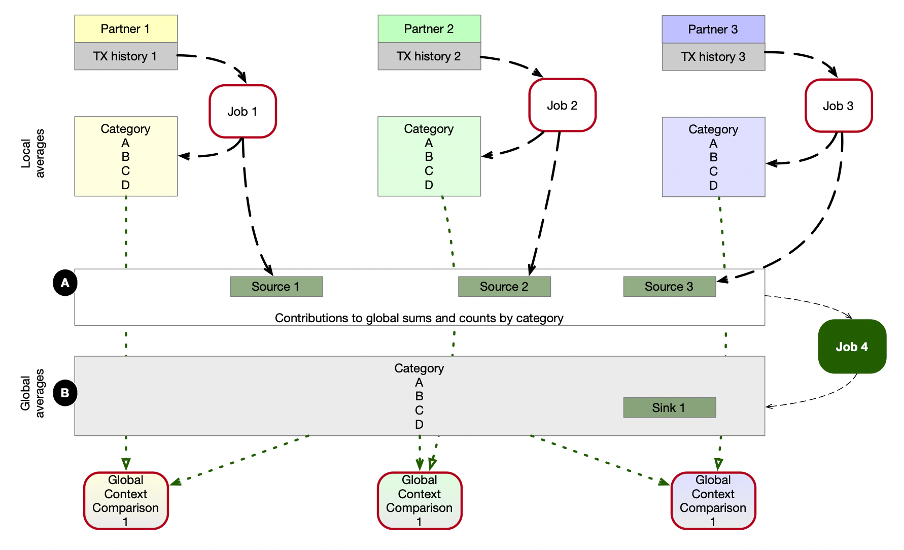
The illustration shows the data flows in such a scenario. Jobs with red border are executed by the participants in isolation within their own data processing environments. But they share some of the data, using publicly accessible Kafka topics, marked by A. Job 4 is the Apache Wayang job in our focus: here we intent to read data from 3 different source systems, and write results into a fourth system (marked as B), which can be accesses by all participants again.
With this in mind we want to implement an Apache Wayang application which implements the illustrated Job 4. Since as of today, there is now KafkaSource and KafkaSink available in Apache Wayang, an implementation of both will be our first step. Our assumption is, that in the beginning, there won’t be much data.
Apache Spark is not required to cope with the load, but we expect, that in the future, a single Java application would not be able to handle our workload. Hence, we want to utilize the Apache Wayang abstraction over multiple processing platforms, starting with Java. Later, we want to switch to Apache Spark.